2 Topic Modeling Techniques You Should Know About
Get an insight into the two modeling techniques that you should know about. Understand the implementation of topic modeling in Python & 2 topic modeling techniques.
Topic modeling is a technology used to find out the topic of the content in the document. Nowadays text summarization is a very common term used to generate a summary of a big document or article to find out its essence and what it is talking about. With that small summary, a reader can decide ‘whether he wants to read the whole document or not.
In the present world, where there is a lot of information and documents available, it is so confusing and time-consuming to choose the most appropriate document for you. To help people get rid of this confusion, topic modeling is used to find the topic of the articles or a corpus of documents to make it easy to choose. Now you don’t need to read the whole document to conclude that ‘if it has what you were looking for or not?. So topic modeling algorithms are the ways to find the topics of a large volume of unlabeled documents.
Topic Modeling Techniques
Here are the topic modeling techniques:
1. Latent Dirichlet Analysis
LDA is one of the techniques used to find out the topic of a set of documents. This evaluation is based on the frequency of words occurring in the document. It helps in finding a reasonably accurate list of topics covered by a set of documents of large volume. One topic modeling example of LDA is finding out the most highlighted topics about India after independence. Suppose we have a large number of articles about India since 1947. Reading all the articles to find the topics, is almost an impossible task to do manually. LDA will scan all the documents to find out the most relevant topics based on their frequency in the corpus.
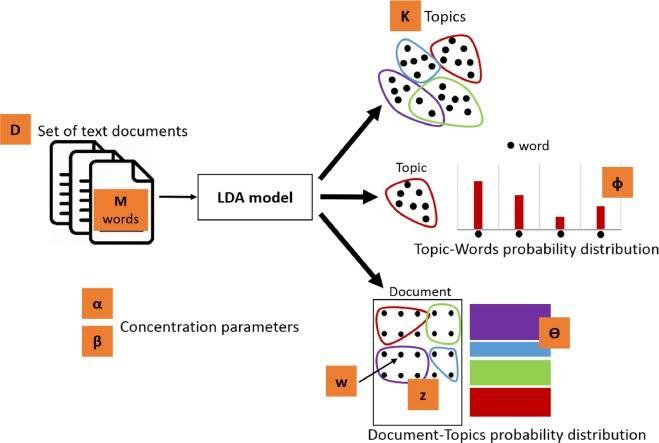
LDA technique involves following steps for implementation:
1. A set of documents is collected from various published articles.
2. Then data cleaning is done which involves
- Tokenizing the documents by converting them into their atomic elements.
- Removing the meaningless words by using stopping filters.
- Different words with the same meaning are merged as one, known as stemming.
The above steps make the data ready for implementing LDA packages on them.
4. Now each word in the provided document corpus is assigned a random topic.
5. Then the documents to topic count is done to find out the number of occurrence of a topic in the documents.
6. Even it is also observed that ‘which and how many times a topics have been assigned to a particular word?’.
7. Now topics to the words are reassigned at each pass so that they can converge to a topic.
8. Then it is calculated ‘how much a document like each topic?’ and ‘how much a topic likes each word’?.
9. Then the two values are multiplied. It gives the area a topic covers in the documents.
This process is repeated iteratively for all the words to come up with the most highlighted topics. LDA implementation does not require any coding. It just needs some function calls to Gensim library. The output will display the most important words in the decreasing order of their frequency.

Parameters of LDA
There are various parameters used by LDA to implement topic modelling:
- Document topic density
- Topic word density
- Number of topics
- Number of topics terms
- Number of iterations
2. Latent Semantic Analysis
Latent refers to the hidden or not directly visible features of a document. LSA is a natural language processing technique to derive meaning from fixed data. It is considered to be as an unsupervised learning technique, as there is no target or label available to make this analysis. It focuses on the inherent features of the text data to create its representation. It also helps in reducing the dimensionality in the content of the data set.
The LSA implementation includes two steps:
- Generate document term matrix
- Perform singular value decomposition on the document term matrix.

Document Term Matrix
Document term matrix is the representation of the document as points or vectors in the Euclidean space. In this matrix, each row represents a document from the corpus and each column represent a word from the dictionary which appear at least one time in any of these documents. So 1 is assigned in the matrix if the word appears in the document and 0 in which it doesn’t. Each of these documents is termed as a vector with elements as a combination of 1 or 0 based on the occurrence of given words in that document.
Singular Value Decomposition
Now singular value decomposition is performed on the document term matrix. It reduces the dimensionality of the original data set by encoding it using these latent features. These features are the topic inherent in the documents of the corpus.
Implementation of Topic Modeling in Python
Implementation in python uses
- Natural Language Tool Kit for preprocessing the data set
- Gensim libraries for LDA model building
- pyLDAvis libraries for topic visualization.
NLTK is used for word processing like removing stock words and getting the corpus ready for further steps.
- Gensim contains a lot of libraries like LSA and LDA.
- pyLDAvis helps in visualization of the topic model interactively. It allows us to change the topics and find probabilities. It also provides us with the Principle Component Analysis by visualization.
- It enables the user to compare the words contributing more to a topic and find the next dimensional weight like the size of the bubble.
- With the increasing buzz of Artificial Intelligence, Machine Learning and Natural Language Processing, businesses that deal with a lot of data daily are incorporating topic modeling algorithms in their process.
- It prevents the employees from the overload of organizing data. AI technology provides a lot of methods to process data and finds out the topic from a large volume of data.
- Topic modeling has its application in many fields that require some sort of research work overtime. It provides a neat way of undertaking e-discovery, understanding social media and scientific data.
- It is also used in natural language processing applications like word sense disambiguation. It also helps in understanding the psychology change over time by analyzing the corpus.
Ready to put this into practice?
Appsierra's expert-supervised QA and AI engineering pods help teams ship higher-quality software faster — with senior accountability and a low-risk pilot. Tell us what you're working on.